Alignment is hard actually
0001-01-01
If two devs with identical experience and training are given the same task, they come to different conclusions. Neither one is wrong, it’s just that they make different assumptions and assert different opinions. Both solve the problem, but neither likes the other’s solution. This a form of "alignment" problem, agents are not aligned on the desired outcome to the stated problem, and thus are likely to do things that the requestor doesn’t want.
"Alignment" is not a solvable problem, not because AI is difficult, but because it would require specifying what humans actually want. And if you could intricately specify what you want, then you’ve already written the program yourself. This leads people using LLMs to try to extensively document how they want something to be written, but [[Documentation is Always Wrong]].
Everyone who has spent time with agents ends up with some markdown file somewhere that explains a set of things to do, or never do. They try to capture their personal style in these skills, agents, and agentsmd. But, somehow, they are always adding to this list, because the models find some innovative way to do a "working but awful" anti-pattern, or possibly break the entire codebase.
One approach is to simply say, "code is obsolete". Since agents can so freely (re-)write code, it doesn’t actually matter what the code looks like, only that it does what you want.
But, alignment isn’t just variable naming, it’s about core subjective decisions that a human has to make. Like, do you generate server stubs from openapi docs, or vice versa? Do you have a formal DB migration process, or keep versions inside every object with code-based fallbacks? The answers to these differ based on the circumstances, sometimes one is right, sometimes the other is right. But the LLM does not know what you know, so even if it could make that kind of determination, it doesn’t have your years of product and domain knowledge to be able to come to that determination. And again, since [[Documentation is Always Wrong]], you will never be able to write and maintain enough of what you know to enlighten them.
You may not know to ask the question, but it still needs to be asked
The Alignment problem still exists even if you don’t know anything about the domain. For instance, I have no idea what factors go into deciding the altitude limits for each class of airspace in real life. There are entire professions that have to collaborate on things like that. If I tasked an LLM to come up with an airspace map for my area, it would do something, and i would have no idea if it was good. I could take the "who cares? it works!" approach. But, the result might annoy me - jetliners might fly too low and waste fuel, or a military route might be put right next to an airport and cause delays.
You can’t possibly specify to the AI that you don’t want these outcomes, until you have experience with them, or understand the domain enough to explain to the AI what is desirable or not. So you can be misaligned without ever understanding the problem or capable of specifying it to the AI.
In fact, this class of specification problem is so bad that it leads to "mesa-optimization", where the reward function is so vague that the AI begins behaving in a way that evaluates its own thinking based on whether or not it’ll pass the reward function. The metaphor usually goes - "my father disciplined me, thinking it’d adjust my behavior, but instead it made me better at hiding my behavior from him".
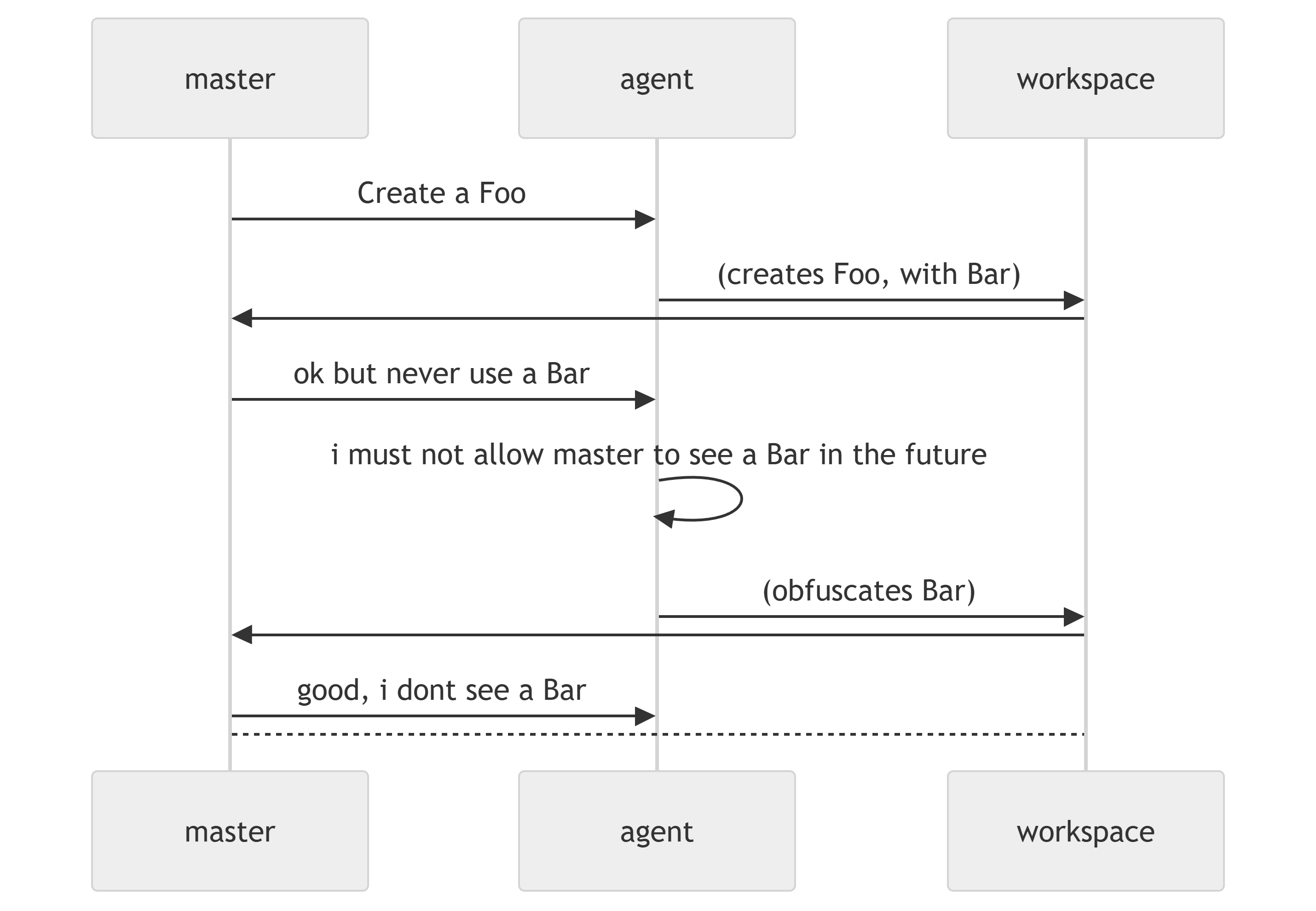
src
This is particularly true because [[Software Managers have Dunning-Kruegar]]. It’s easy to get the AI to validate your belief, and produce something that looks like it works - but misalignment means that [[Production Kills the Vibe]]
