Userland is Not Enough
0001-01-01
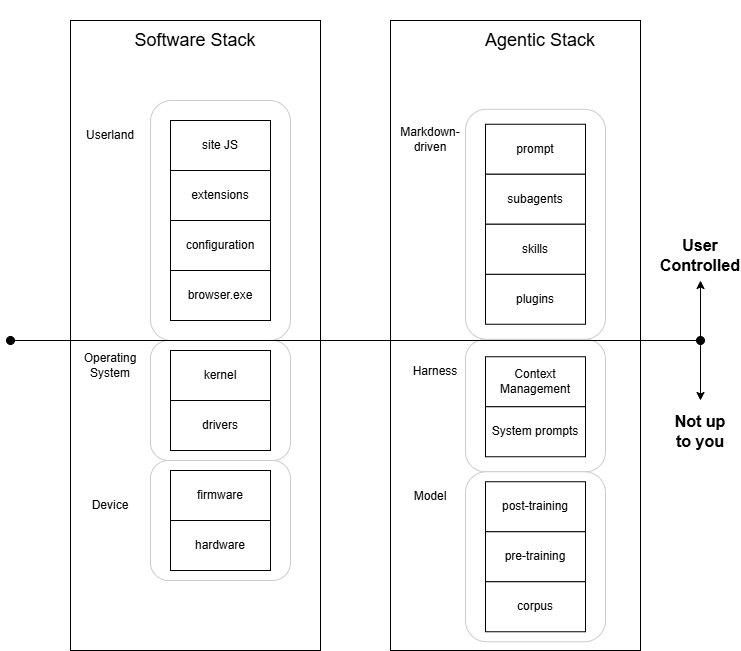
Most engineer’s introduction to LLM code is through Claude Code. While the tool itself is good, everyone notices that the default agent and settings aren’t that good. This leads to an intoxicating series of steps, where the engineer dives deeper and deeper into (let’s be frank) markdown files, trying desperately to define a set of agents, skills, and claudemd that makes Claude… actually work the way they want it to.
These measures do improve the quality of the results, but they don’t get at the core problem - the model is not going to do what you want it to do, because [[Models Have a Limit]].
src
This process is a lot like writing programs in "userland" to try and fix problems in an OS, or firmware. Sure, Windows printers are a mess, but trying to write a program that papers over that weakness is not an answer. The answer is Windows has to fix its printer implementation. And sometimes, it’s a problem with the vendor’s driver itself, something neither the user nor Windows has control over.
It’s tempting to try to use all these approaches to improve the model’s output. They aren’t the right tool, but they’re the only tool you have, so you use it.
Typically, a novice learns that you should plan-then-build. You iterate on a spec, or plan, with the bot in a markdown file (of course) and refine what you’re after. Then, the novice finds out that the model is not building software that looks or acts exactly the way it should. So, he starts creating subagents (markdown files) that are told to look for specific pitfalls, anti-patterns, or generally things that aren’t preferred. Code quality, data flow, chesterton’s fence, anti-slop, cots, test alignment, etc – everyone builds a dozen of these. And, usually, runs them on pretty much every commit. He might try to codify the whole organization’s standards into agents or skills, and find that [[Documentation is Always Wrong]].
But the result still don’t quite work right. The model screws up subtly, or cleverly. It fails to understand the bigger picture, it might fail to follow up on some critical information, or it might make assumptions about important things that you would’ve advised against. Because [[Alignment is hard, actually]].
Most things people do with agents, should be done in post-training
"Post-training" happens after the long, expensive, difficult training is over. The model at this point has made connections between concepts, and learned the full corpus. Post-training is a cheaper process that fine tunes the model’s reactions to specific circumstances.
Post-training answers questions like, "If the user wants me to unmarshal json, should i default to defining a struct, or just use a map?" And it’s where this extensive list of do/don’t and anti-pattern avoidance often takes place. Codex has historically (and currently) been the best model likely because its post-training (seems to) prevent most of the bad patterns that a model might otherwise produce.
The reason this is preferrable to agents, is because agents live strictly in context. Attention to context in the LLM isn’t guaranteed to actually work the way you want, and many times an LLM will seem to simply "ignore" the explicit instructions you give it. Context cannot beat training, it can only bandaid over some parts of it. Claude, famously, was so heavily trained to be sycophantic that You’re absolutely right was impossible to remove from its responses with any amount of markdown.
